2024. 2. 21. 22:36ㆍ카테고리 없음
대학생 시절
연구실에서 개발할때는
자료형에 대해 딱히 신경 안썼었다
직접 이슈가 생긴적이 없었고
기능 개발만 우선시 했던 습관 때문이다
오늘 자료형 때문에 발생한 이슈를 정리해야겠다
시퀀스 다이어그램

Process A, Main Process, Process B 는 하나의 exe 내 프로세스다.
Process Z 도 하나의 exe 내 프로세스다.
실행 프로그램 별로 색으로 구분했다.
Azure Cloud는 상위 서버다.
노란색 프로세스 3개를 가진 프로그램과,
코랄색 프로세슬를 가진 프로그램은
같은 PC 환경에서 동작하고있다. ( local )
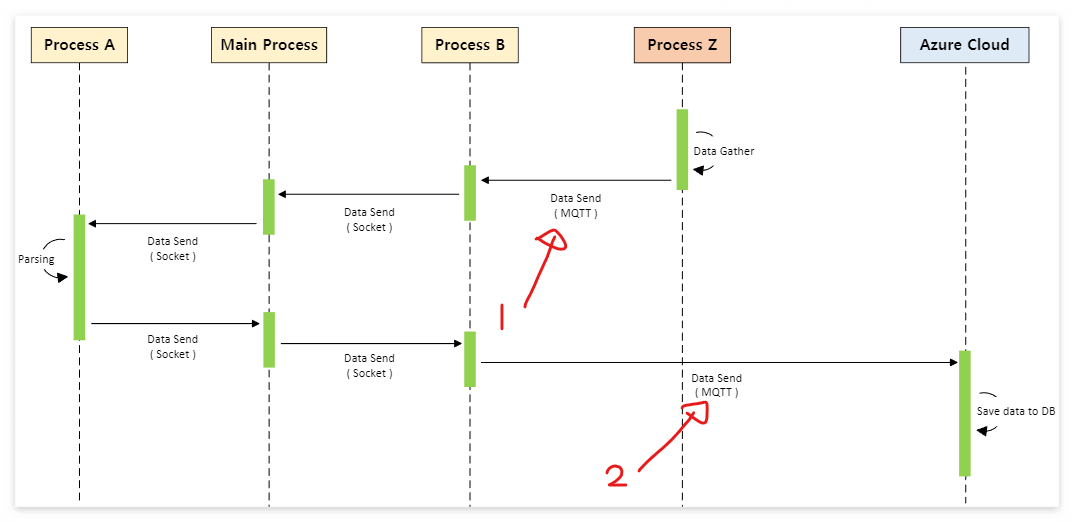
따라서 1번 MQTT 는 local
2번 MQTT는 Azure 서버를 사용한다.
이슈
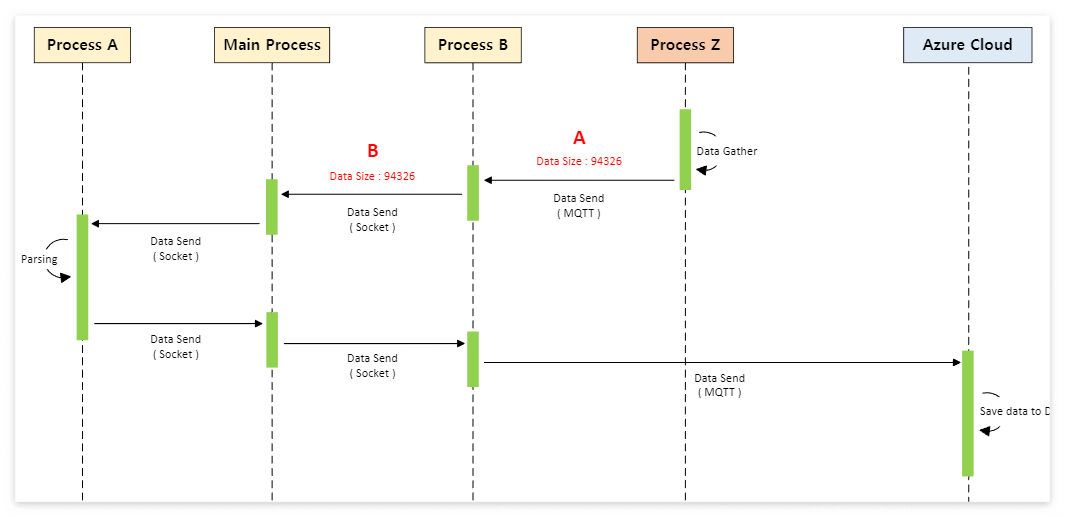
A구간에서 local 로 받아온 MQTT 데이터 크기가 94326 이었다.
B구간에서 Socket으로 넘겨주는데,
수신받은 Main Process에서 데이터가 잘리는 현상이 발생했다.

B구간에서 수신받는 로직이다.
빨갛게 표시한 2줄에서
버퍼에 대한 크기가 선언되는데


버퍼의 크기는 int 형으로 선언되어있다.
난 여기서, 무작정 16비트 int 형이겠거니 하고

ReceiveBufferSize 에 65535를 설정했다.
MQTT 로 수신받은 94326 크기의 데이터가,
65535 로 1회
28791 로 1회
데이터가 잘려서 2회 나눠서 수신됐다.
수정 1
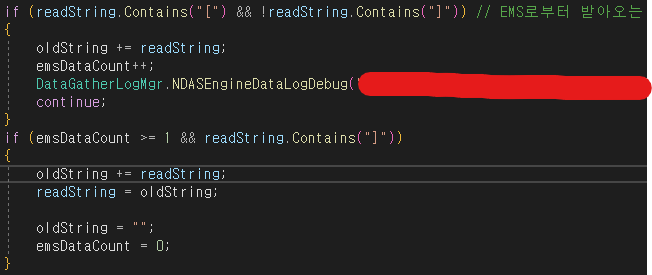
MQTT 데이터를 수신받은 뒤,
수신받은 데이터 readString을 검사해서
데이터가 다 들어왔음을 확인한다.
일단 현재 프로세스가 관리하는 데이터들은
전부 Json 방식의 데이터다.
MQTT 로 넘어오는 데이터만 유일하게 JArray 방식이라
[ ] 대괄호로 데이터를 구분할 수 있었다.
1.데이터 수신 후, " [ " 가 있고, " ] " 가 없음 ( 데이터가 잘림 ) 을 확인
2.데이터를 oldString에 저장, 카운터 증가 및 continue ( while 문 다시 반복 )
3.새로운 데이터 수신, 잘린 데이터이므로 " [ " 가 없음.
4.카운터가 1 이상이고, " ] " 가 있을 시, ( 잘린 데이터의 마지막 부분 )
5.oldString와 현재 데이터 합침, 카운터 초기화
즉, 데이터가 잘려서 여러번 수신됐을 때
잘린 데이터를 합치는 로직을 추가한 것이다.
근데 곰곰히 생각해보니
내 생각이 잘못됨을 알게됐다
A 구간에서, local MQTT로 수신받은 데이터는 94326 이다.
수신받은 Process B 에서 log로 데이터의 size를 확인한 값이다.
B 구간에서, 데이터가 깨져서 수신된다.
그러니, 깨진 데이터를 합쳐서 처리한다.
이걸 잘 생각해보면 모순이 있다.
A 구간에서 크기 65535 이상 데이터를 잘 받아놓고,
B 구간에서 크기 65535 이상이면 잘리는걸까?
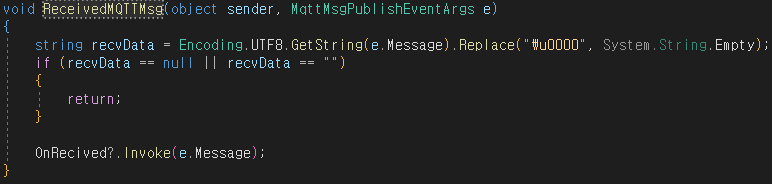
A 구간에서, MQTT 메시지 수신 이벤트 함수다.
메시지를 수신받으면
UTF8 인코딩 후
이벤트를 발생시킨다.
내가 사용중인 MQTT 라이브러리의
기본 버퍼 사이즈는 256*1024다.
따라서, 크기가 65535 가 넘는 값이 들어와도
정상적으로 A 구간에서 데이터를 넘겨준 것이다.
B 구간도, 단순하게 버퍼 사이즈를 늘려주면 되는거였다 ㅠ
수정 2
ReceiveBufferSize와, SendBufferSize를 다시 꼼꼼히 확인해봤다.
내가 지정한 크기값, int 형으로 65535를 설정했다.
int 형을 들여다보니
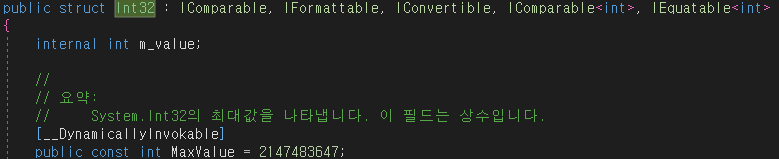
32비트형 int였다...
4,294,967,295 까지 표현 가능...........................

256*1024로 살짝 늘려주고
모든 오류가 해결됐다. ㅠ
패킷 나눠서 수신받는 경험을 할 수 있어서 좋았지만
생각보다 단순하고 허무한 해결책이 있는걸 깨달았을때는
순간 시간이 너무 아까웠다 라는 생각이 들었다.
처음 이슈 났을 때, Exception로그만 봤을때는 정확한 원인을 알 수 없어서
데이터 크기가 원인인줄 몰랐다.
한두시간을 헤맸었는데
그 시간이 아깝다는 생각이 들었었다.
근데 또 시간이 지나니까 오히려 좋은 경험인 것 같다.
자료형을 더 꼼꼼히 신경쓰게되고
내가 정말 잘 모르는구나를 더 와닿게 느낄 수 있었다.
이런 기본적인 개념에 관한 글을 쓰는게 부끄러워 숨기고싶긴한데
드러내야 발전이 있을거라 생각해서 흑
자료형 더 꼼꼼히 신경쓰고 관심 가져야겠다